End-to-End Learning for Multimodal Emotion Recognition in Video with Adaptive Loss
IEEE MultiMedia, Vol. 28 (2), pp. 59-66, April-June 2021
Abstract:
This work presents an approach for emotion recognition in video through the interaction of visual, audio, and language information in an end-to-end learning manner with three key points: 1) lightweight feature extractor, 2) attention strategy, and 3) adaptive loss. We proposed a lightweight deep architecture with approximately 1 MB, which for the most crucial part, accounts for feature extraction, in the emotion recognition systems. The relationship in regard to the time dimension of features is explored with temporal convolutional network instead of RNNs-based architecture to leverage the parallelism and avoid the challenge of vanishing gradient. The attention strategy is employed to adjust the knowledge of temporal networks based on the time dimension and learning of each modality’s contribution to the final results. The interaction between the modalities is also investigated when training with adaptive objective function, which adjusts the network’s gradient. The experimental results obtained on a large-scale dataset for emotion recognition on Koreans demonstrate the superiority of our method when employing attention mechanism and adaptive loss during training.
| Full paper | Code |
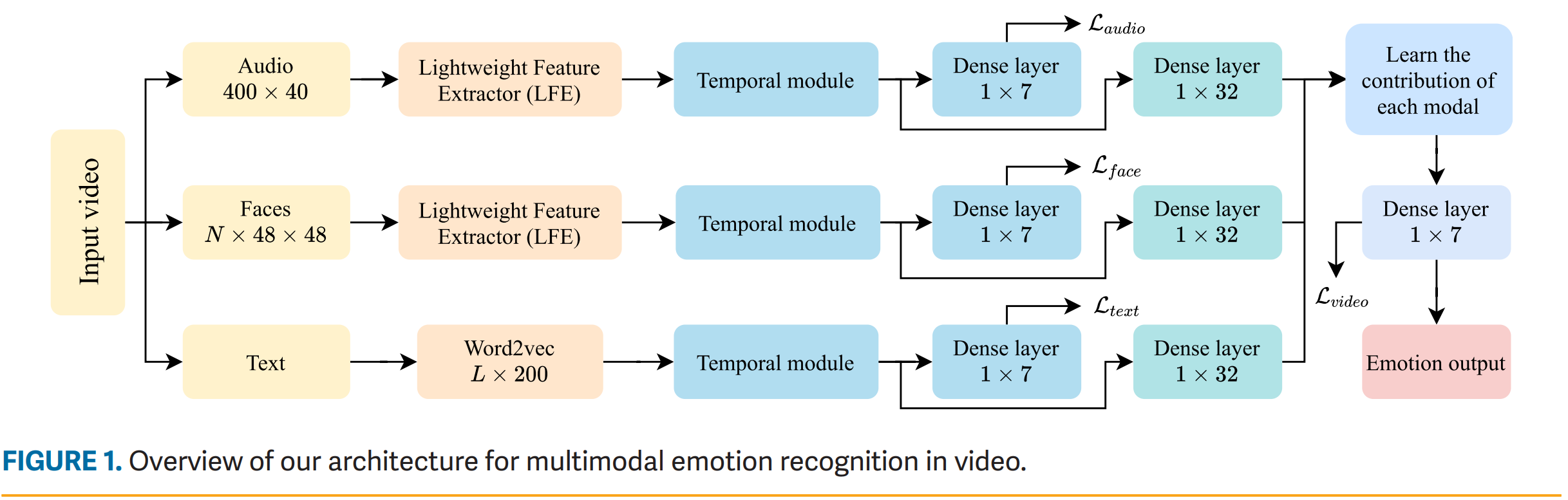
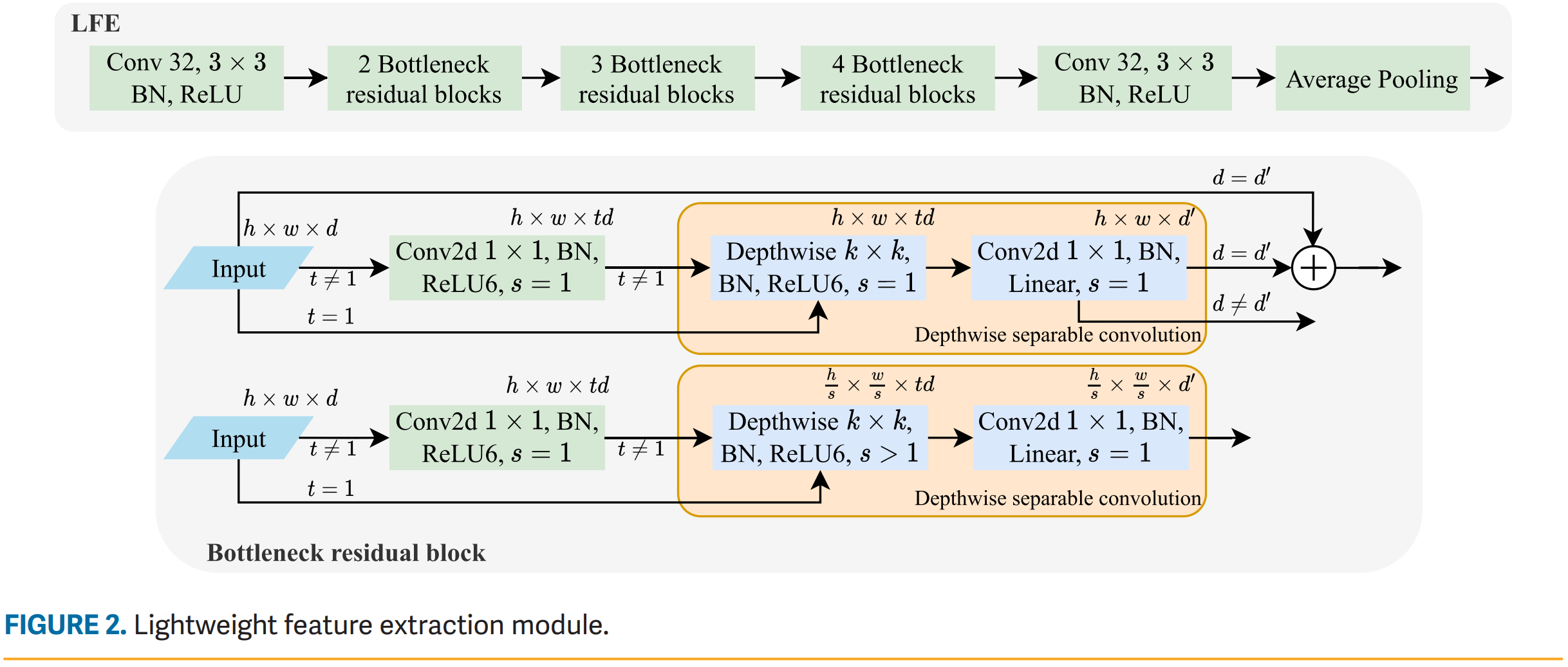
Evaluation
-
CMU-MOSEI (CMU Multimodal Opinion Sentiment and Emotion Intensity)
F1 score and Weighted accuracy (wA):
\[wA = \frac{TP(N/P) + TN}{2N},\]where TP and TN are true positive, false negative, P and N are the toal number of positive, negative.
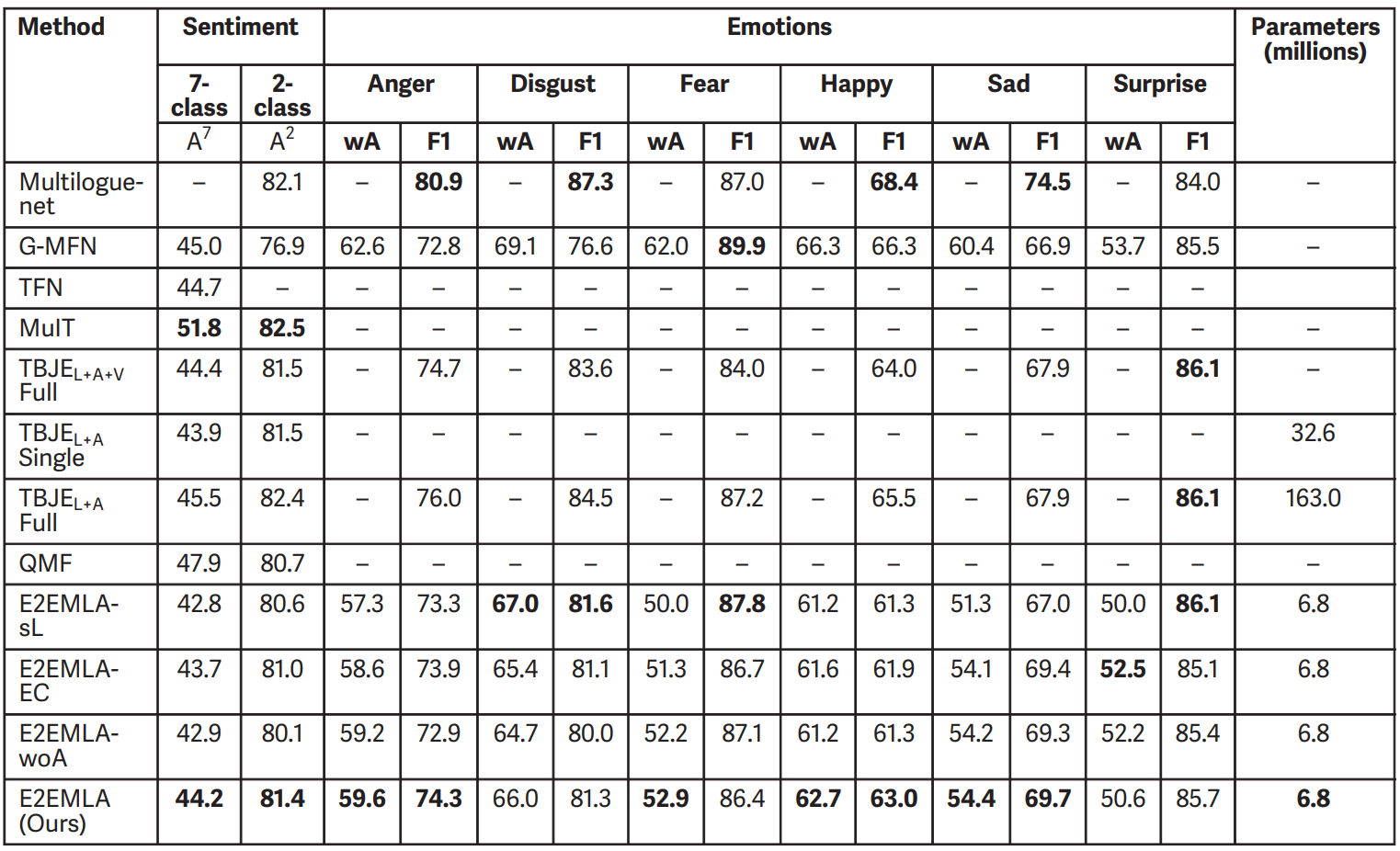
Evaluation results on CMU-MOSEI compared to prior works. -
MERC2020 (Korean Emotion Recognition Dataset)
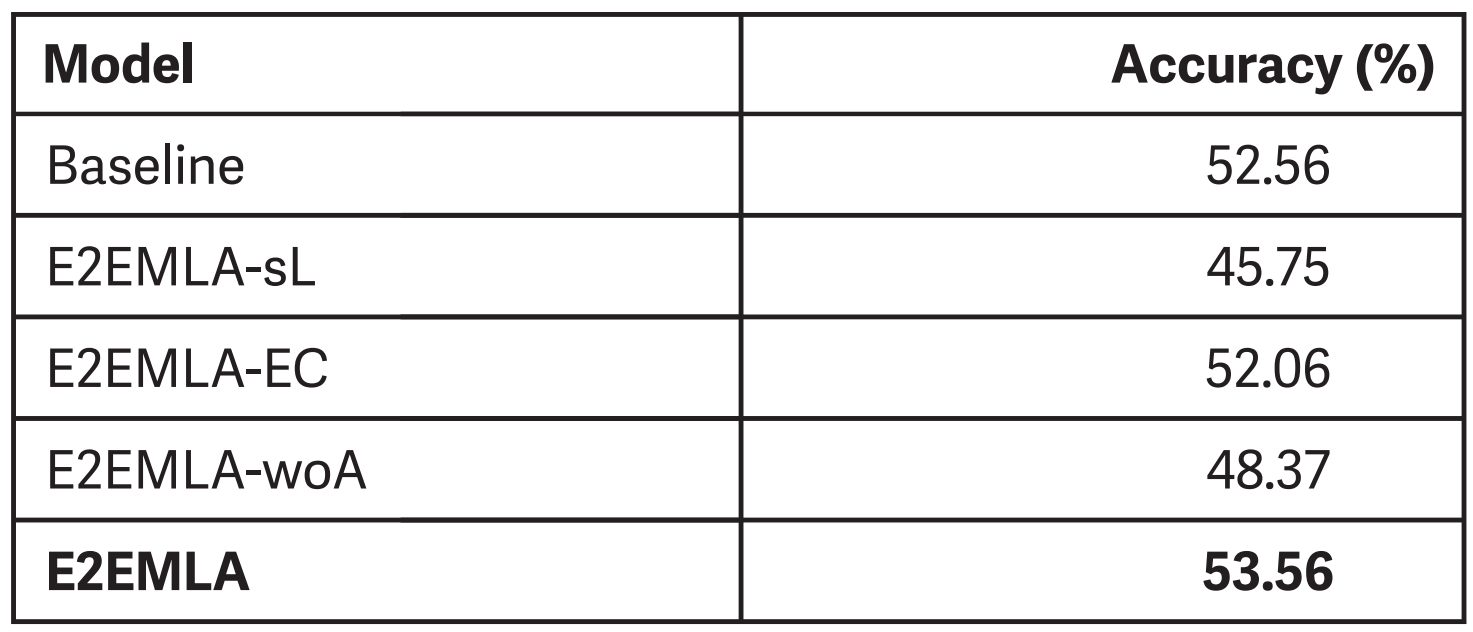
Evaluation results on MERC2020 validation set.
Citation
V. T. Huynh, H. -J. Yang, G. -S. Lee and S. -H. Kim, “End-to-End Learning for Multimodal Emotion Recognition in Video With Adaptive Loss,” in IEEE MultiMedia, vol. 28, no. 2, pp. 59-66, 1 April-June 2021, doi: 10.1109/MMUL.2021.3080305.
BibTeX
@ARTICLE{9431699,
author={Huynh, Van Thong and Yang, Hyung-Jeong and Lee, Guee-Sang and Kim, Soo-Hyung},
journal={IEEE MultiMedia},
title={End-to-End Learning for Multimodal Emotion Recognition in Video With Adaptive Loss},
year={2021},
volume={28},
number={2},
pages={59-66},
doi={10.1109/MMUL.2021.3080305}}