Prediction of evoked expression from videos with temporal position fusion
Pattern Recognition Letters, Vol. 172, pp. 245-251, August 2023
Abstract:
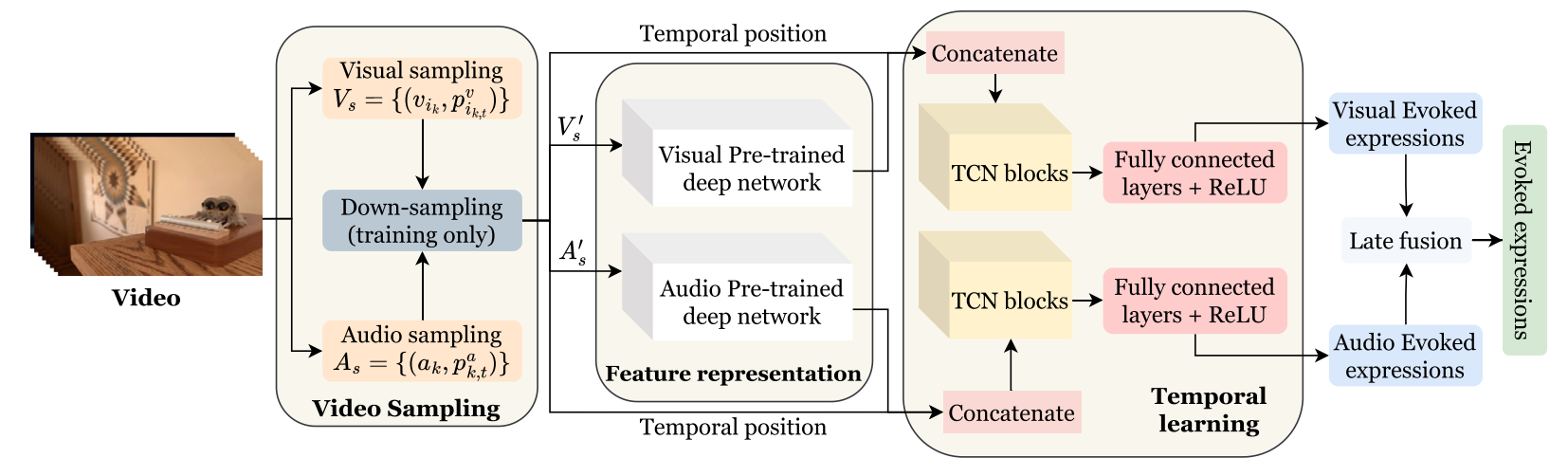
This paper introduces an approach for estimating evoked categories expression from videos with the temporal position fusion. Pre-trained models on large-scale datasets in computer vision and audio signals were used to extract the deep representation for timestamps in the video. A temporal convolution network, rather than an RNN-like architecture, was applied to explore temporal relationships due to its advantage in memory consumption and parallelism. Furthermore, to address the noise labels, the temporal position was fused with the deep learned feature to ensure the network differentiates the time steps when noise labels were removed from the training set. This technique helps the system gain a considerable improvement compared to other methods. We conducted experiments on EEV, a large-scale dataset for evoked expression from videos, and achieved a score of 0.054 in terms of Pearson correlation coefficient as a state-of-the-art result. Further experiments on a sub set of LIRIS-ACCEDE dataset - MediaEval 2018 benchmark, also demonstrated the effectiveness of our approach.
Evaluation
-
EEV (Evoked Expressions in Video Dataset)
Our team SML won 1st place
 in EEV 2021 challenge:
in EEV 2021 challenge: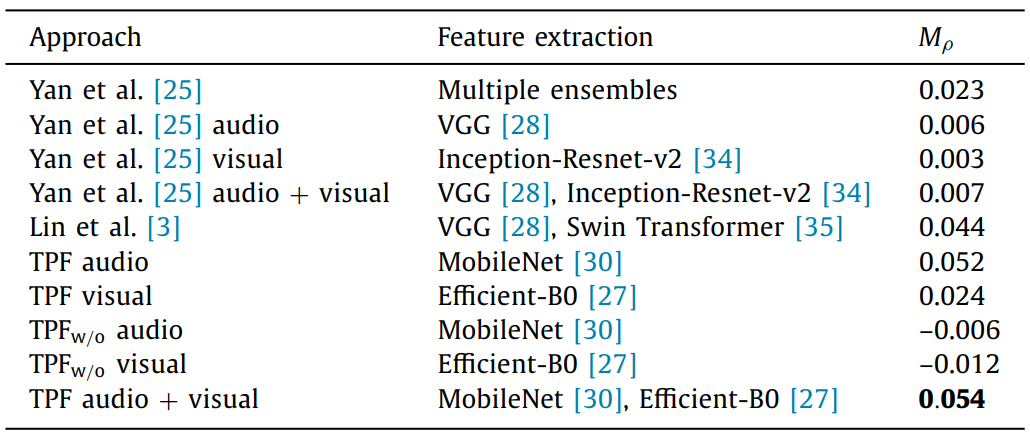
Evaluation results on EEV dataset compared to other works. -
MediaEval 2018 (Emotional Impact of Movies)
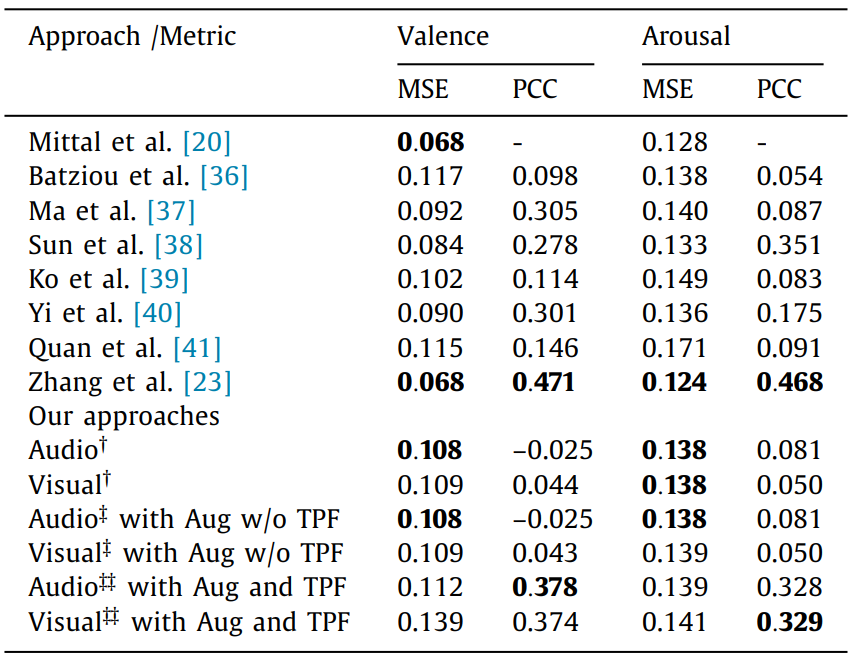
Evaluation results on MediaEval 2018 dataset compared to other works.
Citation
V. T. Huynh, H. -J. Yang, G. -S. Lee and S. -H. Kim, “Prediction of evoked expression from videos with temporal position fusion,” in Pattern Recognition Letters, vol. 172, pp. 245-251, August 2023, doi: 10.1016/j.patrec.2023.07.002
BibTeX
@ARTICLE{HUYNH2023245,
title = {Prediction of evoked expression from videos with temporal position fusion},
journal = {Pattern Recognition Letters},
volume = {172},
pages = {245-251},
year = {2023},
issn = {0167-8655},
doi = {https://doi.org/10.1016/j.patrec.2023.07.002},
author = {Van Thong Huynh and Hyung-Jeong Yang and Guee-Sang Lee and Soo-Hyung Kim},
}